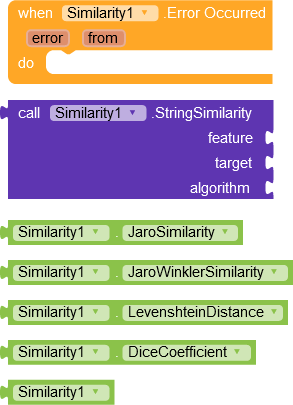
feature : String
target : String
algorithm : property
###Algorithms
1.JaroSimilarity
2.JaroWinklerSimilarity
3.LevenshteinDistance
4.DiceCoefficient
Return score
###Algorithms (property)
.
In computer science and statistics, the Jaro–Winkler similarity is a string metric measuring an edit distance between two sequences. It is a variant of the Jaro distance metric (1989, Matthew A. Jaro) proposed in 1990 by William E. Winkler.
The Jaro–Winkler distance uses a prefix scale
p
{\displaystyle p}
which gives more favourable ratings to strings that match from the beginning for a set prefix length
ℓ
{\disp...
In computer science and statistics, the Jaro–Winkler similarity is a string metric measuring an edit distance between two sequences. It is a variant of the Jaro distance metric (1989, Matthew A. Jaro) proposed in 1990 by William E. Winkler.
The Jaro–Winkler distance uses a prefix scale
p
{\displaystyle p}
which gives more favourable ratings to strings that match from the beginning for a set prefix length
ℓ
{\disp...
In information theory, linguistics, and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. The Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other. It is named after Soviet mathematician Vladimir Levenshtein, who defined the metric in 1965.
Levenshtein distance may also be referred to as edit distance, although that ...
The Dice-Sørensen coefficient (see below for other names) is a statistic used to gauge the similarity of two samples. It was independently developed by the botanists Lee Raymond Dice and Thorvald Sørensen, who published in 1945 and 1948 respectively.
The index is known by several other names, especially Sørensen–Dice index, Sørensen index and Dice's coefficient. Other variations include the "similarity coefficient" or "index", such as Dice similarity coefficient (DSC). Common alternate spellings...
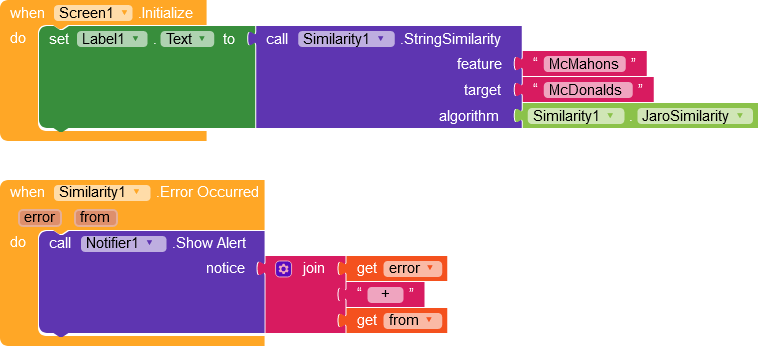
Error return and source
In this demo I am trying to find out the similarities between McMahons and McDonald’s by algorithm Jaro
I hope I explained the benefit of the extension
com.aemo.similarity.aix (13.7 KB)
similarity.aia (15.9 KB)
If you like my work, please support me
https://ko-fi.com/mhooda
9 Likes
Shreyaa:
Nice extension
Ammaraldewani:
Amazing
Thanx @Shreyaa & @Ammaraldewani
2 Likes